6 tips to optimize storage costs for your Postgres databases
Simple strategies to lower your storage bill

As your data grows, so does your storage bill. Here are 6 quick tips that can help you streamline your storage usage, keeping your Postgres database running lean.
1. Remove unused indexes
Indexes are crucial for Postgres query performance, but they also consume storage space. Over time, as applications evolve, indexes often become obsolete or redundant, yet they continue to occupy valuable storage space and even add overhead to write operations.
For example, let’s say you have a Postgres table storing orders. Initially, you focused on troubleshooting shipping issues, so you created an index on the shipped column to speed up finding unshipped orders (WHERE shipped = false). After a few months, the shipping problems are resolved. Your focus now shifts to analyzing overall sales performance, requiring aggregates across all orders and identifying high-value orders quickly. The unused index on shipped still consumes storage and adds overhead to inserts/updates, even though it’s no longer relevant for key queries.
To identify unused indexes, you can leverage the Postgres pg_stat_user_indexes and pg_index views. These views provide insights into index usage statistics, including the number of index scans, which can help you pinpoint indexes that are not being used for query optimization.
2. Reduce storage duplicities
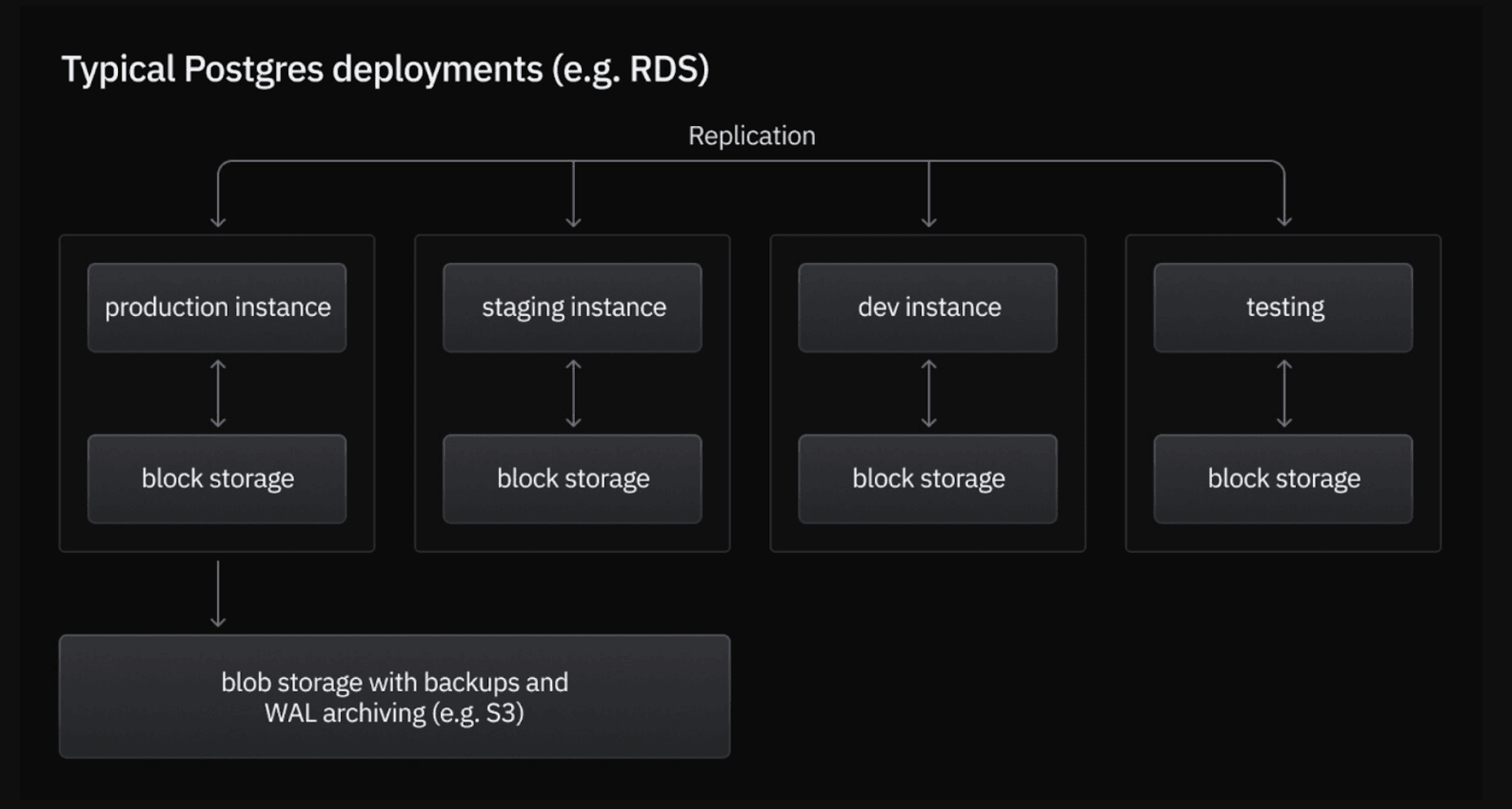
In production settings, it’s common practice not just to maintain a single production database but also to run multiple data copies for staging, development, and testing purposes. This significantly increases the overall storage costs; every additional copy translates directly into more storage space, multiplying the expenses.
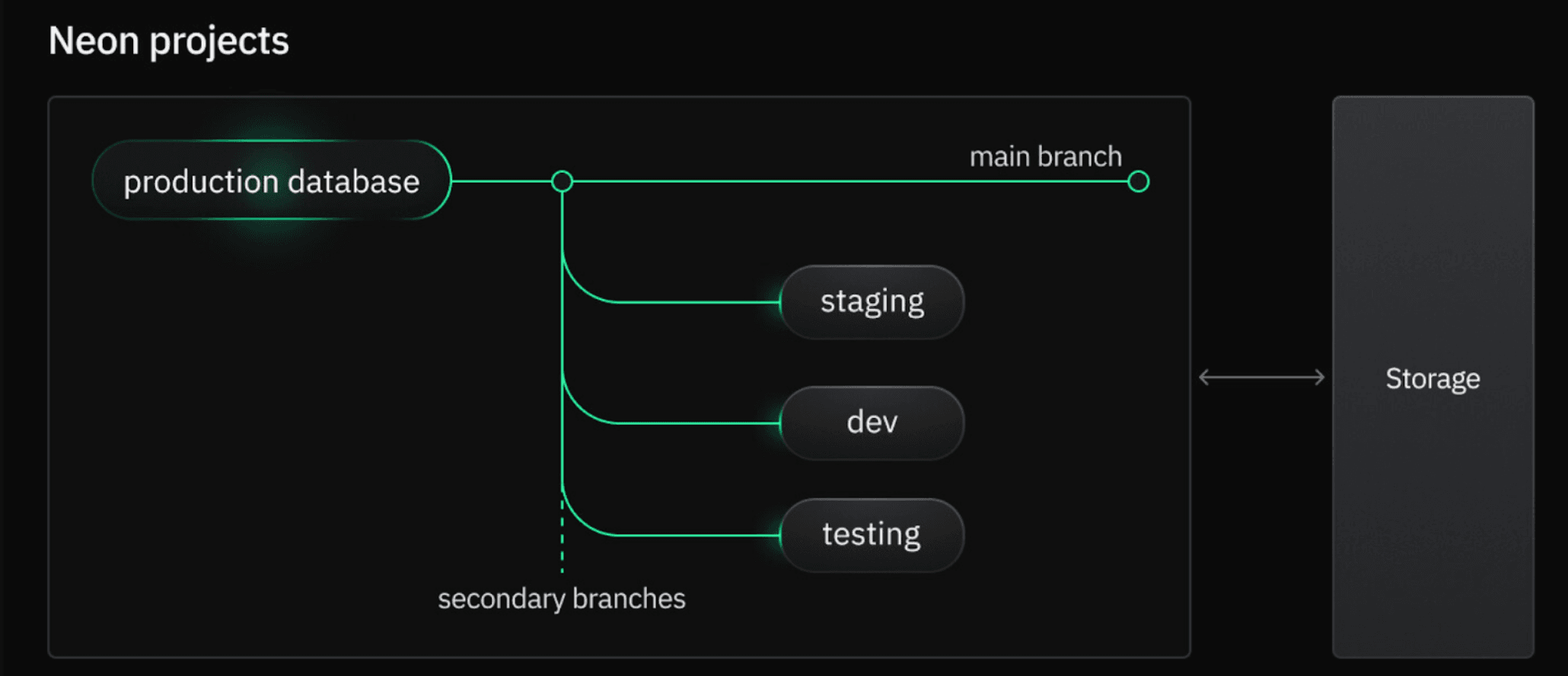
If you’re in Neon, you can use database branching to avoid this. The custom storage architecture of Neon, allows for the creation of database copies via copy-on-write (just like you’re used to with code in Git). This means that database branches share the same underlying data as the main database branch until changes are made, and as a result, you can have numerous development, testing, and staging environments that mirror your production database without paying extra for storage.
3. Use efficient data types (if you can)
Every data type in Postgres has its own storage requirements, so it’s better to avoid selecting a data type that is larger than necessary. For example:
- Postgres offers a range of numeric types, including
INTEGER,NUMERIC,REAL, andDOUBLE PRECISION. Each has its use case, butINTEGERtypes are often sufficient for counts and identifiers and use less space than floating-point types. - If you’re storing small integers, you can use the
SMALLINTtype instead ofINTEGERorBIGINT, as it uses less space.
4. Order your columns from largest to smallest
In Postgres, the physical order of columns in your table definitions also can impact storage. This is due to the alignment requirements of different data types, where each type is aligned at memory addresses that are multiples of their size. This ensures efficient data retrieval and adherence to memory and storage management protocols but can introduce padding to meet these criteria, leading to unused space within your database.
To mitigate this, order your table columns from the largest to the smallest data type. By doing so, you minimize the padding necessary for alignment, thus reducing wasted space. For example, consider a Postgres table designed to store user information:
CREATE TABLE user_info (
user_id SERIAL, -- 4 bytes
name VARCHAR(100), -- variable size
profile_pic_url TEXT, -- variable size, potentially large
registration_date DATE -- 4 bytes
);If we wanted to apply the optimization strategy of ordering columns from largest to smallest, you might redesign the table like this:
CREATE TABLE user_info_optimized (
profile_pic_url TEXT, -- variable size, potentially large
name VARCHAR(100), -- variable size
registration_date DATE, -- 4 bytes
user_id SERIAL -- 4 bytes
);5. Adjust your history retention period in Neon
Neon automatically retains a history of changes across all branches within a project, empowering users with the capability to restore data to any point within the defined retention period. Therefore, the size of storage for a Neon project will be calculated as the sum of two variables:
- Data size (size of all the tables in Postgres databases)
- History size (corresponding to the WAL size up to the configurable history retention period)
The default retention periods vary by pricing plan (24 hours for Free, 7 days for Launch, and 30 days for Scale). If you’re in Launch or Scale plans, you could consider configuring a shorter retention period, which leads to storage savings.
But before you jump right on it, consider the potential impact on your Point-In-Time Recovery (PITR) capabilities. In Neon, you can revert changes or recover lost data by restoring a branch to an earlier state within the retention window. You can pinpoint the exact moment needed for restoration, down to the millisecond. But reducing the history retention period narrows this window of opportunity for recovery, so make sure tol balance between the need for storage optimization and the ability to recover from unintended data alterations or loss.
6. Consider fine-tuning autovacuum
Postgres autovacuum automates the process of reclaiming storage space after rows are updated or deleted (“dead tuples”). If you have a highly transactional workload, you might want to consider a more frequent autovacuum schedule than the configured by default.
If you suspect bloat is being an issue for you, you can check for long-running transactions that might be impeding autovacuum from properly running. You can use `pg_stat_activity` to identify transactions that are running longer than expected (e.g., over 10 minutes).
Running Postgres? Try Neon
Neon’s approach to storage can transform your Postgres experience, making it more efficient, agile, and cost-effective. Request an Enterprise trial to get a 30-day unrestricted access to the platform.